WarpHelix — AI 生物医学研究智能体平台
以超光速推动生命科学研究
生物医学研究正面临一场效率危机
全球每年发表超过 300 万篇 生物医学论文,公共数据库中沉淀了 PB 级 的组学数据。然而,绝大多数研究人员却无法有效利用这些资源——不是因为缺乏科学直觉,而是因为缺乏工具和技能。
🔴 三大核心痛点
1. 生信人才严重短缺
生物信息学已成为现代生命科学研究的"必修技能",但现实是:
- 全球生信人才缺口持续扩大,高校培养速度远远跟不上需求
- 一个合格的生信工程师年薪 30-80 万,中小型实验室根本请不起
- 即使是大型科研机构,一个生信团队也要服务几十个课题组,排队等分析是常态
- 结果:大量"湿实验"做完了,数据分析成了瓶颈,论文发不出去
2. 工具碎片化,学习曲线陡峭
生物医学研究涉及数百种专业软件和数据库:
- 做基因组分析要学 BLAST、BWA、GATK、samtools...
- 做单细胞分析要学 Scanpy、Seurat、CellRanger...
- 做药物发现要学 RDKit、AutoDock、ADMET 预测工具...
- 做蛋白质分析要学 AlphaFold、STRING、分子对接工具...
- 每个工具都有不同的安装方式、数据格式、参数设置
- 结果:一个完整的分析流程,光环境配置就要花几天,真正的科学问题反而被搁置
3. 分析流程不可复现
科研领域的可复现性危机尤其严重:
- 手动操作步骤容易遗漏,参数设置靠"经验"
- 不同分析师对同一数据可能得出不同结论
- 审稿人要求复现分析时,经常发现"跑不通了"
- 结果:浪费时间、浪费经费,拖慢整个研究进程
生物医学研究最大的瓶颈,不是没有数据,而是没有足够多、足够好的人来分析数据。
WarpHelix 如何解决这些问题?
WarpHelix 的核心理念:让每一个研究人员都拥有一个 7×24 在线的"超级博后"。
不需要编程,不需要配置环境,不需要学习几十种工具——用自然语言描述你的研究问题,WarpHelix 自动完成从规划到执行到报告的全流程。
🧠 核心架构:Think → Execute → Observe → Solution
WarpHelix 基于斯坦福大学 Biomni 框架构建,采用 LLM 推理 + 检索增强规划 + 自动代码执行 的深度集成架构:
关键差异:WarpHelix 不是一个"问答机器人",而是一个真正能"动手做实验"的 AI 智能体。 它不只是告诉你"应该怎么做",而是直接帮你做完。
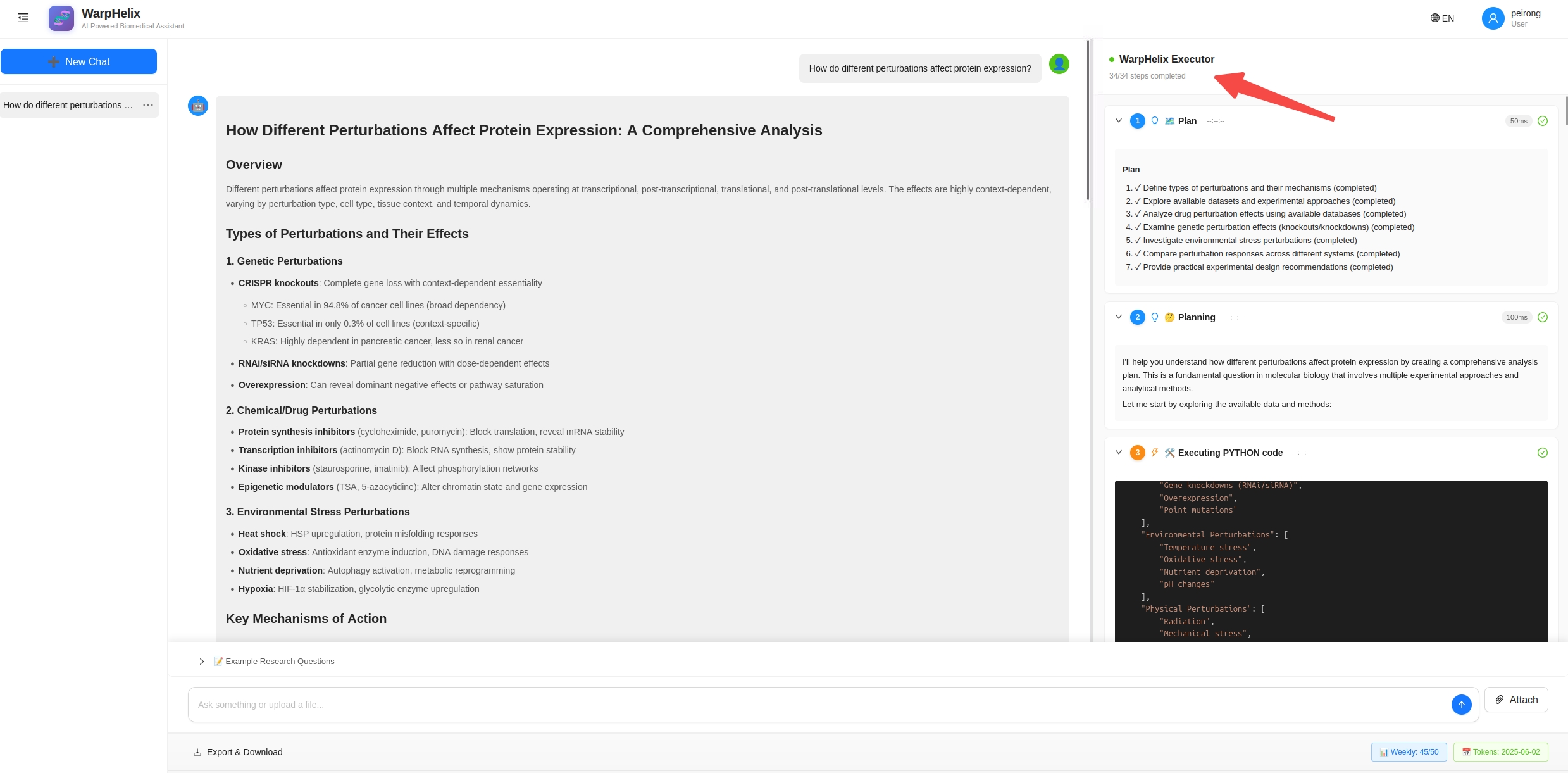
为什么 WarpHelix 能做到?
🔬 150+ 专业工具,开箱即用
WarpHelix 系统性地从上万篇生物医学论文中挖掘和集成了 150+ 专业工具,覆盖生物医学全链路——这也是 Biomni 框架的核心创新:Action Discovery(动作发现)机制。
不同于传统的"人工选择几个常用工具",Biomni 通过 AI 自动从学术文献中发现、评估并集成专业工具,构建了目前最全面的生物医学 AI Agent 工具生态。
| 分析领域 | 代表性工具 | 典型任务 |
|---|---|---|
| 序列分析 | BLAST、BWA、samtools | 序列比对、变异检测 |
| 基因组学 | BEDTools、liftOver、VCF工具 | 区间运算、坐标转换 |
| 单细胞 | Scanpy、AnnData | scRNA-seq 分析、细胞注释 |
| 蛋白质 | AlphaFold、STRING | 结构预测、互作网络 |
| 药物发现 | RDKit、AutoDock、TDC | 分子对接、ADMET 预测 |
| 文献检索 | PubMed、Semantic Scholar | 跨库检索、趋势分析 |
🌐 25 个生物医学子领域全覆盖
从基因组学到癌症基因组学,从分子克隆到罕见病诊断,从微生物组到蛋白质工程——WarpHelix 是目前覆盖领域最广的生物医学 AI Agent。
查看完整领域列表
| # | 领域 | 典型任务 |
|---|---|---|
| 1 | 🧬 基因组学 | 遗传变异解读、基因优先级排序、调控元件查询 |
| 2 | 💊 药物发现 | ADMET 预测、药物重定位、分子对接模拟 |
| 3 | 🔬 单细胞生物学 | scRNA-seq 细胞注释、Perturb-seq 分析 |
| 4 | 🧪 分子克隆 | 克隆方案设计、引物设计 |
| 5 | 🏥 罕见病诊断 | 辅助诊断、文献证据关联 |
| 6 | 🦠 微生物组 | 微生物组分析、群落结构解析 |
| 7 | 🧫 蛋白质科学 | 结构预测、相互作用网络分析 |
| 8 | 📊 癌症基因组学 | cBioPortal 数据查询与分析 |
| 9 | 📚 文献挖掘 | 跨数据库检索、研究趋势分析 |
| 10 | 🧬 表观基因组学 | DNA 甲基化、组蛋白修饰分析 |
| 11 | 🔗 基因调控网络 | 转录因子结合、基因调控推断 |
| 12 | 📈 群体遗传学 | 选择信号检测、群体结构分析 |
| 13 | 💉 免疫学 | 免疫组库分析、新抗原预测 |
| 14 | 🧪 代谢组学 | 代谢通路分析、代谢物鉴定 |
| 15 | 🧫 蛋白质组学 | 蛋白质定量、修饰位点分析 |
| 16 | 🌿 植物生物学 | 植物基因组分析、作物改良 |
| 17 | 🧬 RNA 生物学 | ncRNA 预测、RNA 结构分析 |
| 18 | 📊 空间转录组学 | 空间基因表达分析 |
| 19 | 🧬 进化生物学 | 系统发育分析、分子进化 |
| 20 | 🏥 临床基因组学 | 临床变异解读、用药指导 |
| 21 | 🔬 结构生物学 | 蛋白质结构解析、分子模拟 |
| 22 | 💊 化学信息学 | 分子描述符计算、化合物筛选 |
| 23 | 🧬 功能基因组学 | CRISPR 筛选分析、基因功能注释 |
| 24 | 🏥 精准医学 | 分子分型、个体化治疗方案 |
| 25 | 📊 生物统计学 | 生存分析、临床试验设计 |
对比:有 WarpHelix vs 没有 WarpHelix
| 场景 | 传统方式 | 使用 WarpHelix |
|---|---|---|
| 遗传变异分析 | 手动查 ClinVar、gnomAD,写脚本解析 VCF → 2-3 天 | 一句话提问,自动查库、分析、出报告 → 5 分钟 |
| 单细胞 RNA-seq | 配环境、装包、调参、写流程 → 1-2 周 | 上传数据,描述需求 → 15 分钟 |
| 药物 ADMET 预测 | 安装 RDKit、TDC,写预测脚本 → 2-3 天 | 给 SMILES 结构,直接预测 → 3 分钟 |
| 蛋白质对接 | 配置 AutoDock、准备结构文件 → 3-5 天 | 指定目标蛋白,自动完成 → 10 分钟 |
平均分析效率提升 5-10 倍,部分场景提升超过 100 倍。
企业级特性:不只是原型,而是生产级平台
WarpHelix 不是一个实验室 demo。在开源 Biomni 框架基础上,我们进行了深度企业级改造:
👥 多用户与权限管理
完整的用户注册、认证和权限体系。管理员后台支持用户管理、对话审计、系统配置一站式管理。
💰 精确的用量计量
Token 用量精确统计(输入/输出分别计量),用户级别配额分配与消耗追踪,超额自动暂停。
🔧 多模型灵活切换
- AWS Bedrock(Claude Sonnet 4):主力模型
- 通义千问(DashScope):国内低延迟备选
- 管理员可随时切换,无需重启
📁 智能文件管理
上传文件按类型自动分类,Agent 执行环境自动挂载用户文件,智能预览与分析。
📤 全流程可追溯
一键导出完整对话(含执行步骤、代码和结果),Markdown 格式,支持归档、审计和分享。
🔒 数据安全:私有化部署,数据不出内网
生物医学研究数据高度敏感。WarpHelix 从架构层面保障安全:
- 用户数据严格隔离 — 每个用户的对话、文件、分析结果相互独立
- 研究数据不用于模型训练 — 您的数据绝不会被用于训练 AI 模型
- 支持完全私有化部署 — 所有数据留在企业自有服务器
- 全链路自主可控 — 从 LLM 推理到数据存储,全部署在客户环境
- 一键部署 — 支持 AWS / 阿里云 / 本地服务器
典型应用案例
案例 1:遗传变异解读 — 从数据到报告 5 分钟
研究者提问: "帮我分析这组基因变异数据,重点关注与帕金森病相关的变异。"
WarpHelix 自动执行:
- 解析上传的 VCF 文件,识别变异位点
- 查询 ClinVar、gnomAD 获取变异注释和人群频率
- 检索 PubMed 相关文献,关联临床证据
- 评估变异致病性(ACMG 标准)
- 生成完整分析报告 + 可视化图表
案例 2:单细胞 RNA-seq 全流程分析
研究者提问: "分析这个 Perturb-seq 数据集,找出关键的基因扰动效应。"
WarpHelix 自动执行:
- 加载 AnnData 格式数据,执行质控和标准化
- PCA 降维 + UMAP 可视化
- 细胞类型注释(基于标记基因)
- 差异表达分析,识别扰动响应基因
- 通路富集分析,揭示扰动的生物学效应
- 生成完整报告,附带所有可视化结果
案例 3:药物成药性评估
研究者提问: "评估这个化合物的成药性:CC(=O)Oc1ccccc1C(=O)O"
WarpHelix 自动执行:
- 解析 SMILES 结构,计算分子描述符
- 预测 ADMET 属性(吸收、分布、代谢、排泄、毒性)
- Lipinski 五规则评估
- 对比同类药物数据
- 给出成药性评分和优化建议
案例 4:蛋白质结构预测与分子对接
研究者提问: "预测 ACE2 蛋白的结构,并模拟与候选药物的对接。"
WarpHelix 自动执行:
- 获取 AlphaFold 预测结构
- 检测潜在配体结合位点
- 准备配体结构并执行分子对接
- 分析结合模式、亲和力和关键相互作用
- 可视化对接结果
技术底座
WarpHelix 基于斯坦福大学 Biomni 开源框架构建。Biomni 是学术界首个通用型生物医学 AI Agent 框架,提供了统一的工具发现机制和执行环境。
WarpHelix 在此基础上进行了深度企业级改造,新增多用户管理、配额计量、私有化部署、文件管理等生产环境必需能力,使其从科研原型升级为可落地的企业级产品。
联系我们
如需了解更多信息、申请试用或商务合作:
- 📧 邮箱:peirongw@foxmail.com
- 🌐 官网:website.autoinfra.cn
- 🏢 公司:曲速引擎互联网络科技有限公司
长按保存图片,发送到朋友圈
WarpHelix — 让 AI 成为每一位生命科学研究者的超级助手